Introduction
The purpose of this assignment is to learn how to run a regression in SPSS, interpret regression analysis, and to predict results using regression. Another purpose of this assignment is to learn how to effectively map standardized residuals in ArcGIS and connect statistics and spatial outputs. There were two separate parts to this assignment, the first using Excel and SPSS to conduct regression analysis to see if crime rates per 100,000 are dependent on free school lunches within town X. Then, using the regression equation, an estimate was made for the crime rate of a town that that had 23.5% of students receiving free lunch.
Part two entails using single linear regression, multiple linear regression, and residual analysis to assist the City of Portland in seeing what demographic variables influence 911 calls as well as helping a private construction company determine the most suitable location for the construction of a new hospital.
Part one: Crime and Free Student Lunches
Methodology:
A local news station claims that as free lunch increases, crime rate also goes up. Finding out of this new claim is correct or false would be done using the Excel data titled "Crime," and running a regression analysis in SPSS. Then, using the outputs for the analysis, we can interpret and explain the data as seen below in figure 1.
* It's important to note that free student lunches are the independent variable and that crime rate is the dependent variable. This helps us determine if rates of free lunch (independent variable) influences crime rates (dependent variable).
Questions to be answered:
1. Is the news station's claim correct using SPSS?
2. If a new area of town was identified as having 23.5% with a free lunch, what would the corresponding crime rate be?
3. How confident are you with the results of question 2?
 |
| Figure 1: SPSS regression analysis results for the provided crime data |
The Model Summary table gives an r^2 value of .173, which is very far from 1, indicating a weak relationship. The r^2 value explains how much the independent variable (PerFreeLunch) explains the dependent variable (CrimeRate) on a scale of 0-1, 0 showing no explanation and 1 showing full explanation. In other words, since the r^2 value is .173, the percent of free lunches only explains 17.3% of the crime rate.
Using a regression equation of y = a + bx format was the next step in understanding the crime rate in a new area of town and identified with 23.5% free lunches. Y represents the dependent variable, a represents the constant (the point where the best fit line crosses the y axis or when x = 0), x represents the independent variable, and b represents the slope of the line or the regression coefficient. With this equation, an estimation of the crime rate can be calculated. Y = 21.819 + 1.685 * 23.5%. The equation indicates that if a town has a free student lunch rate of 23.5%, its' estimated crime rate using the regression equation is 61.417 per 100,000 people.
The significance level in the PerFreeLunch row under Coefficients table is .005, indicating that there is a statistical relationship between crime rate and free student lunch rate which is significant at the 95% level. The reason there is a statistical relatipnship is because of the significant level is below .05, we reject the null hypothesis (which states there is no relationship) and accept the alternative, which states there is a relationship. In essence, the news station is technically right when it claims that as free lunch rate goes up, crime goes up.
Lastly, there is little confidence in the results of 61.417 crimes out of 100,000 people because the r^2 value of .173 is low.
Part Two: Portland 911 Calls and Potential New Hospital Location
We were provided the following scenario:
"The City of Portland is concerned about adequate responses to 911 calls. They are curious what factors might provide explanations as to where the most calls come from. A company is interested in building a new hospital and they are wondering how large an ER to build and the best place to build it."
Methodology:
Step 1: Single Regression in SPSS
We were to choose three independent variables of our own choice to compare with the dependent variable of Calls (number of 911 calls). I chose LowEduc, Unemployed, and ForgnBorn and ran three seperatesingle regression analysis against the dependent variable of Calls. LowEduc represented the number of people without a high school diploma. Jobs represented the number of jobs in the census tract. ForgnBorn represented foreign born population. After running a single regression analysis, we will be able to show how well the independent variable explains the number of 911 calls
Step 2: Run Multiple Regression in SPSS
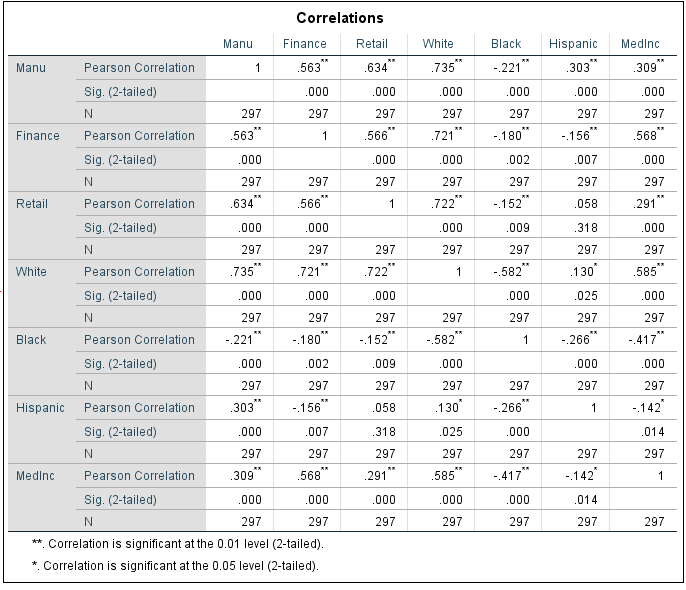
I ran a multiple regression analysis using the independent variables of Jobs, Renters, LowEduc, AlcoholX, Unemployed, FornBorn, Med Income, and CollGrads. Again, the dependent variable was number of 911 calls. * I included the option of collinearity diagnostics while running the analysis.
Step 3: Stepwise Approach with Multiple Regression
The stepwise approach is used to find the variables that influence the linear equation the most. With it, you're able to find independent variables to take out and SPSS automatically chooses the variables it things influence the equation the most. For this particular approach, the computer chose Renters, lowEduc, and Jobs as the three variables which influence the linear equation the most.
Step 4: Choropleth Map and Residual Map
I opened Arcmap in order to map the number of 911 calls per census tract and added the Portland census tract layer. I then went into symbology and changed it to choropleth map of 911 calls.
I then mapped the residuals by going into the toolbox and going to the spatial statistics. After getting to spatial statistics, I selected modeling spatial relationships and chose ordinary least squares (OLS). I then selected the census tract as an input and set the unique field id to UniqID and set the dependent variable to number of calls as well as the independent variable to LowEduc.
Results:
Single Variable Regression
LowEduc Independent Variable
 |
| Figure 2: Regression analysis output for 911 calls and LowEduc |
The above image (figure 2) shows that there is positive relationship between 911 calls and the LowEduc variable based on the linear equation of y = 3.931+ .166x, meaning that 911 calls will increase by .166 for each new uneducated person in that area. Additionally, the r^2 value for this regression is .567, which is a relatively high r^2 value. Again, this means that 911 calls by LowEduc people is 56.7% of the time. When it comes to hypothesis testing, we reject the null hypothesis because the significance level is under .05 meaning there is not a relationship between 911 calls and uneducated people. In this case, we're in favor of the alternative, which says there is a relationship between 911 calls and uneducated people.
Unemployed Independent Variable
 |
| Figure 3: Regression analysis for 911 calls and Unemployed |
Above (figure 3) shows that the equation of y=1.106+.507x can be helpful by looking at the slope of the equation which is .507. This mean that 911 calls will increase by .507 for every unit increase in unemployment. Additionally, the r^2 of .543 is relatively high. Unemployment rate explains 54.3 % of the calls in the census tracts. The significance level of .000 is under .05 so the null hypothesis would be rejected. This means we reject the null hypothesis that there is no relationship between unemployment rate and 911 calls and instead favor the alternative hypothesis which says that there is a relationship between the unemployment rate and 911 calls.
Foreign Born
 |
| Figure 4: Regression analysis for 911 calls and foreign born |
The above image (figure 4) shows that the r^2 value is .552 which indicates that there is a relatively strong relationship between foreign born individuals and the number of 911 calls. It also means that 55.2% of the foreign born citizens can help explain the variation in the number of 911 calls. Since the significance level is .000 we reject the null saying that there is no relationship and instead favor the alternative saying that there is a relationship between the number of 911 calls and number of foreign born citizens. Lastly, the B value of foreign born persons of .08 says that for every time there is one more foreign citizens in a census tract, the number of 911 calls will increase by .08 calls.
* All three of these outputs help understand if there is relationships between the dependent variable and the independent variables, it doesn't do a good job of helping the construction company decide a new place for a hospital.
Multiple Regression
This part of step two dealt with multiple regression. A multiple regression analysis was performed on the data and also included collinearity diagnostics which was under the statistics setting. The number of 911 still was the dependent variable, but multiple independent variables were used, hence the name multiple regression analysis. The outputs can be seen below in figures 5 and 6.
 |
| Figure 5: Multiple regression output 1 |
 |
| Figure 6: Multiple regression analysis output 2 |
Additionally, looking at collinearity can be seen by looking at the bottom of of the Collinearity Diagnostics table. The eigen values close to 0 tell you to investigate farther onto the condition index. If the condition index is higher than 30, then there is collinearity. When there is collinearity, a variable needs to be eliminated. Fortunately, in this case, no values under the condition index are above 30 which means there is no collinearity. If collinearity was present, you would then take the variable with the value on the bottom row closest two 1, eliminate it, and re-run the multiple regression analysis.
Multiple Regression Analysis with Stepwise Approach
The below images, images 7,8, 9, and 10 are all the outputs from the stepwise multiple regression. In stepwise regression, only the variables that aren't collinear will be used. In other words, the stepwise method effectively eliminates the collinear variables in the process of computing the results.
The three variables that helped drive the equation most were Renters, LowEduc, and Jobs. The r^2 values of these three variables combined was .771 as seen on the Model Summary of figure 7. Again, those three variables help explain 77.1% of the 911 calls made. When assessing this in a linear equation, I used 911 calls = Renters*.024+LowEduc*.103+Jobs*.004. All these variables had a positive slope which means they all had a positive relationship with the amount of 911 calls made.
Lastly, looking at the "Beta" values helps explain which variable is most influential and which variable is least influential. The stepwise approach helps you see which Beta values are the highest, with LowEduc, being the highest, Jobs, being the second, and Renters being the third among the three.
 |
| Figure 7: Stepwise output 1 |
Figure 8 (below) shows the coefficients table. The most important part of this table is in section 3, which places all three variables together. Here, all the significance levels are under .05, indicating that the null hypothesis is rejected and that there is a relationship between these three independent variables (Renters, LowEduc, and Jobs) with the number of 911 calls.
Figure 9 (below) shows the variables that were not included in the stepwise output. The variables AlcoholX, Unempolyed, ForgnBorn, MedIncome, and CollGrads were those variables.
Maps
Figure 10 below shows the map depicting 911 calls per census tract in Portland Oregon to help better understand spatially where all the calls are coming from. This map didn't have to be standardized to population because each census tract populates the same number of people. We see a couple notable clusters of tracts showing where the calls are coming from. The cluster of 5 tracts in the north-central part of this map have between 57 and 176 calls from 911. Also, the large tract in the southeast part of the city receives a high amount of 911 calls. The center of the map receives a medium amount of calls, between 19 and 56.
This map also helps show the construction company which area to choose a location for the new hospital. The most suitable location appears to be in the middle of the cluster of the 5 tracts in the north-central part of this map. That way, emergency services could respond faster to where the majority of 911 calls are coming from.
 |
| Figure 8: Stepwise output 2 |
Figure 9 (below) shows the variables that were not included in the stepwise output. The variables AlcoholX, Unempolyed, ForgnBorn, MedIncome, and CollGrads were those variables.
 |
| Figure 9: Stepwise output 3 |
 |
| Figure 10: Stepwise output 4 |
Maps
Figure 10 below shows the map depicting 911 calls per census tract in Portland Oregon to help better understand spatially where all the calls are coming from. This map didn't have to be standardized to population because each census tract populates the same number of people. We see a couple notable clusters of tracts showing where the calls are coming from. The cluster of 5 tracts in the north-central part of this map have between 57 and 176 calls from 911. Also, the large tract in the southeast part of the city receives a high amount of 911 calls. The center of the map receives a medium amount of calls, between 19 and 56.
This map also helps show the construction company which area to choose a location for the new hospital. The most suitable location appears to be in the middle of the cluster of the 5 tracts in the north-central part of this map. That way, emergency services could respond faster to where the majority of 911 calls are coming from.
 |
| Figure 10 - Number of 911 Calls per Census Tract in Portland, Oregon |
*For the map below, I used the LowEduc variable, because it has the highest r^2 value.
Figure 11 below shows the standard deviations of the residuals for the LowEducvariable. A residual is the amount of deviation of each point from the best fit line (or regression line). This map shows how the independent variable (LowEduc) predicts the dependent variable (911 calls).
The equation 911 calls = .166* LowEduc + 3.931 predicts the number of 911 calls. The darker the red and darker the blue, the worse the equation did at predicting the number of 911 calls. Census tracts in red are where there's a higher standard deviation of residuals, meaning that the regression equation under-predicted the number of 911 calls in these areas. The census tracts in blue were the areas that had a lower standard deviation of the residuals, meaning that the regression equation over-predicted the number of 911 calls in these areas.
The more yellow a census tract is, the better job the equation did at predicting the number of 911 calls for that particular census tract.
* Some of the census tracts in this map such as the two dark red tracts also overlap the same census tracts that received a high number of 911 calls in the chloropleth map.
 |
| Figure 11: Low Education Residual Map |
 |
| Figure 12 - Renters, Low Education, and Jobs Map |
Conclusion:
Part two of the assignment explained single regression, residuals, and multiple regression while using data from Portland Oregon as an example. The data from SPSS as well as the maps created in ArcMap helped me determine a suitable area for a new hospitable to be built, which was in the central part of Portland, where the majority of 911 calls were coming from.
Throughout the assignment, there was a slight difference between the methods of regression analysis performed. The multiple regression using the enter method used all of the variables and showed how factors, like multcollinearity can influence the results making them less accurate than the stepwise method. In the end, both methods resulted in the showing of the independent variable that influenced where the 911 calls came from.












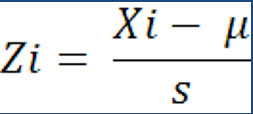











{kind=link}